Earlier this month, I attended the first Flynn meet-up in San Francisco, where the project was presented by its authors. Here’s what I have to say about it.
Important reminder: this post hasn’t been sponsored, endorsed, approved, or anything, neither by my employer (Docker Inc.) nor by the Flynn team. All opinions expressed here are my own.
Flynn? Docker? What?
Docker is an Open Source runtime for Linux Containers. It has been released in March 2013 by Docker Inc. (my employer), and since then, many projects have been based on (or integrated) with it.
Linux Containers being a very good component for Platform-as-a-Service systems, multiple Open Source PAAS were started on top of Docker. Deis is one of them; Flynn is another. Until very recently, there wasn’t a lot of technical details available about Flynn; so I wanted to know more – and the first Flynn meet-up in San Francisco, hosted by Twilio, was the best place to get that information!
For more information about who develops Flynn, how it’s funded, etc., just refer to the project website. I’ll try to cover only technical and architectural topics here.
Flynn technical overview
… or, at least, as I understand it. You’ve been warned :-)
General architecture
A Flynn cluster (or grid) is composed of multiple Docker hosts. Each Docker host will run a number of Docker containers, each holding a “service appliance”. A service appliance is a basic function useful to the whole cluster.
There will be service appliances to deal with scheduling, load balancing, code builds, code execution, etc.
Each service appliance can be deployed (and possibly scaled) individually.
Layer 0 / Layer 1
Flynn is broken down in two layers. Layer 0 provides basic services: host management, scheduling framework, and service discovery. This can be used standalone; for instance if you need something to manage a cluster of Docker machines, without the whole PAAS business on top of it. Layer 0 currently uses Go RPC to communicate (but this will be replaced by a cross-platform RPC system later).
Layer 1 contains everything else that is needed to implement the PAAS itself. PAAS-specific concepts (applications, builds…) are implementend in Layer 1, and don’t exist in Layer 0.
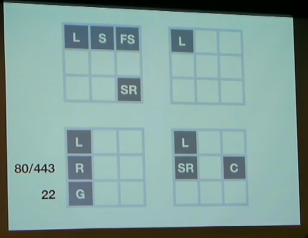
The Grid: the 4 large squares are hosts, the small squares are service appliances. L, for instance, is Lorne, the host management service.
Bestiary of Service Appliances
Here are some of the service appliances. The first two implement “Layer 0”, and everything else is “Layer 1”.
Lorne is the host service. There will be one instance of it on each host in the cluster. It interfaces with Docker. If I understand correctly, it’s an adapter between Flynn discovery/naming/etc. facilities and Docker.
Sampi is the scheduling service. “Scheduling” here means “given the current state of the grid, and the current resource allocation on each node, where should I run this new job, which needs such and such resources?”. To quote the authors: “this does a job similar to Mesos, but for 1000x less lines of code”. To be more accurate, Sampi itself doesn’t do any scheduling; but it presents a consistent view of the cluster (and resource usage) to the actual schedulers, and serializes transactions. In other words, it prevents two concurrent schedulers (or two concurrent operations by the same scheduler) from putting the cluster in a state where resource constraints wouldn’t be satisfied anymore. This is inspired by the Google Omega paper. The real schedulers are implemented on top of Sampi; there are currently two tiny schedulers implemented in the controller API (to support basic scaling and one-off jobs), and something more robust will be added later.
There is a git frontend. It’s a generic SSH server, able to accept git-over-SSH connections, receive git pushes, and then ship them to other parts of the grid. Given that Flynn author Jeff Lindsay is also the author of Dokku and gitreceive, that part should work very well.
The controller exposes the API used to control the whole thing.
The router is a HTTP and TCP load-balancer for inbound traffic. For HA purposes, there should obviously be multiple instances of that guy across the whole grid. As far as I understand, this appliance works closely with the service discovery mechanism – which is expected, since it has to track the location of backends across the cluster as services are created, scaled, and destroyed.
There is also a slug builder and a slug runner. I’m less familiar with Heroku’s funked up terminology, but I expect that the slug builder will take some code (previously received and stored by the git frontend), build it (remember that in the case of Python, Ruby, and other interpreted langauges, “build” often means “install dependencies expressed by pip, setuptools, Gemfile, etc.), and store it as a “slug”. Then the slug runner will somehow instanciate one or multiple containers (depending on scaling parameters) to execute the code with its dependencies.
Principles of Service Appliances
The global idea is that each appliance should perform only a small, simple task, and compose nicely with others. To use the words of the authors, appliances should “focus on a single function, but be optimally minimal”.
They should do one thing, and do it well, rather than combining multiple features. That allows to scale them separately, and to replace a specific component more easily. A very good example is the builder and runner duo. In the early days, the dotCloud PAAS combined both functions in a single component: compute resources were allocated across the cluster, containers were created, then the build process happened in situ; i.e. the container building an app was the same as the one running the app. This was fine for small, un-scaled apps; but it was very inefficient for apps with dozens of containers, since the build process would be replicated N times. Later, the snapshotting builder was deployed; it orchestrated the builds on separate containers, stored the build artefacts, then deployed them on the runtime. As a result, builds were faster, more reliable, and hitless upgrades of applications became possible.
Another principle in Flynn is that each service appliance should have an API. Anyone who has worked with distributed or large-scale systems will take this as granted; but still, it’s good to remind that APIs are essential to automation and orchestration. You can script API calls much easier than you can script ttys, SSH commands, web forms, or clicks in GUIs.
Additionally, appliances should use the service discovery mechanism of the platform, so they can be discovered by other services. Using service discovery also means avoiding hard-coded API endpoints and other bad habits that will bite you when scaling or replicating an existing setup.
Appliances should also clusterable, i.e. scalable for performance and/or reliability.
They should be self-contained – which means that they should not rely on other components when it’s not necessary. I also believe that this is very important, especially when your organization scales out, and different teams (or maybe just different developers) assume ownership and responsibility for different services. When something is down (or doesn’t behave properly), the people maintaining it should be accountable for it. If the service cannot perform as intended because it depends on another component, it should identify the issue and report it accordingly, and, if possible, degrade gracefully. Consider as an example an online shop. If it uses a 3rd party service to perform searches, an outage of that 3rd party service shouldn’t take down the whole website. Search features will be unavailable, but everything else should continue to work. Likewise, in a PAAS, an outage of the build service will prevent you from deploying new versions of your apps, but shouldn’t affect scaling, metrics, or basically the function of existing apps.
Last but not least, appliances should be pluggable. It should be possible to replace a single service with a different implementation without rewriting everything else. A typical example is the routing component. The authors of Flynn told us that it would be straightforward to replace their router with something custom based on Nginx or HAProxy if need be. This particular example rings a bell. Recently, I discussed with the team from Yandex working on the Cocaine project, which integrates with Docker, and one of their questions was “we need to handle hundreds of requests per second on this specific system, so how can we bypass the default networking model and use ours instead?”. One size doesn’t fit all: since no system will be able to cater for everyone’s needs, just make sure that you can replace it with a more suitable version!
Those principles are good not only for Flynn, not only for PAAS, but for most distributed systems out there.
Service discovery
Service discovery is a key part in any distributed system, so it deserves a section of its own.
Etcd
Etcd is a highly-available key/value store, similar to Zookeeper, except that it is based on the Raft algorithm instead of Paxos. From my (arguably limited) experience with both systems, Etcd is much easier to deploy and operate (but just see for yourself).
Flynn uses etcd as a backend for the service discovery mechanism. As said above, etcd is based on the raft protocol, which is a strong consensus protocol. In other words, it will allow writes as long as at least 50% of the cluster is alive and connected.
Flynn also uses etcd to store configuration information for its various components.
Interestingly, etcd has been developed by the CoreOS project, which is… also based on Docker. It’s a small world we live in.
sdutil
There was a pattern that I found particularly interesting. Usually,
interfacing with an existing service discovery system is complex, and
requires extensive modifications in your code. So Flynn comes with
a tool named sdutil, which can wrap any existing TCP server to
plumb it with the service discovery mechanism, like this:
sdutil exec www:8080 /path/to/www/daemon --daemon-options...
This will run your daemon with specified flags, and, assuming that it
runs on port 8080, it will inform the service discovery mechanism
that the www service is running here. If the daemon crashes, exits,
or whatever, sdutil will detect this, and unregister the service.
More details available on the sdutil repository.
What’s next?
To quote the authors, “Flynn is not a PAAS yet; it is a Docker scheduler” – but it’s getting there. The roadmap is ambitious. In 2014, Flynn should acquire the following features:
- log aggregation
- infrastructure cloning
- autoscaling and provisioning (hybrid cloud)
- permissions and access control
- datastore appliances
What are those “datastore appliances”? I’m getting there in the next section.
How do I run e.g. PostgreSQL, ElasticSearch…?
With a datastore appliance. (Told you!)
If I understand correctly the model proposed by Flynn, you will have to run multiple Docker containers: some of them will be data nodes (e.g. PostgreSQL servers, masters and slaves), and some of them will be manager nodes (exposing an API to manage the service).
This reminds me a little bit of the Heroku plugin model: data services are not regular Heroku (or Flynn) apps; they are implemented “on the side” and provide a service that can be consumed by apps.
Interesting parallels with the dotCloud PAAS
There are many similarities between Flynn and dotCloud. This is not very surprising, since they both implement a PAAS. Actually, many components are mapped one-to-one:
- dotCloud also has a per-host container manager;
- dotCloud also has a routing layer to handle load-balancing and scaling for HTTP and TCP services;
- dotCloud also has a SSH endpoint to handle git, mercurial, and rsync code uploads;
- dotCloud also has a component implementing a REST API to interface with the outside world;
- dotCloud also has a builder (to transform source code into a ready-to-run image) and a runner (to execute those images);
- the dotCloud scheduler works a bit differently, but conceptually, there is one as well.
The key differences would be in the service discovery mechanism: dotCloud doesn’t use etcd (which didn’t exist 3 years ago). It uses Riak as a data store, and relies on ZeroRPC for intercomponent communication. The use of ZeroRPC (rather than a classic REST API) allowed us to develop and deploy distributed services extremely quickly, since it made possible to call remote code transparently, without having to abstract it with a RESTful interface. On the other hand, it also means that the code is much more entangled: when it’s cheap and convenient to call the service next door, I mean next host, you do it – and the result is a higher interdependency of the components.
From a user point of view, another key difference is the way to persist state. If you have used Heroku, you know that you cannot persist anything without relying on a 3rd party service (like S3, or, most frequently, the PostgreSQL add-on). And if you have used dotCloud, you know that conversely, each scaled instance of a service has its own local storage that you can retain across successive deployments. Flynn implements both, at different levels. Containers implementing service appliances can have persistent storage (that doesn’t get removed when the container is terminated, and can be re-used by other containers), but apps on top of Layer 1 will initially be stateless.
When building and operating the dotCloud platform at scale, we learned (the hard way) that stateful containers are much more complex to get right. When a container is stateless, you can destroy it, move it elsewhere, scale it at will. If it is idle, it can be removed, and redeployed later. When a container is stateful, you can’t do that anymore. You can stop it when idle, but you can’t destroy it – otherwise, its data is lost. Migrating it to another host means redeploying its code (which is easy) but also moving its data (which is harder, and can take an long time if there is a lot of data). It cannot be scaled as easily, since new instances won’t have the same data.
Of course, it means that each database has to be implemented through a specific service appliance. But that’s a very acceptable tradeoff, especially if service appliances are properly interoperable. The Flynn project can then bootstrap the process with some service appliances, and the community can add more. This wasn’t an option for dotCloud, where only specific parts of the PAAS were Open Source, preventing implementations of internal components by the community.
Conclusion: what did I think of it?
As a potential PAAS user, I would say that Flynn will be a serious option for people with medium to large-ish apps running on traditional PAAS like Heroku (or dotCloud, provided that all service appliances exist for all your stateful services). Just like “private cloud” made sense for people who needed the ability to spin VMs with specific constraints (location, latency, performance, cost…), “private PAAS” will make sense for people who need the same flexibility with apps.
As a devops/sysadmin operating a PAAS, I really like the whole concept and architecture. As often, the devil is in the details, but at least the overall plan makes a lot of sense, and I wouldn’t be afraid of operating a platform like that. (Then again, keep in mind that I have been part of the core team of dotCloud for 3 years, so my views on what it takes to operate a PAAS might be biased.)
As a Docker user, I’m a bit less happy, because it doesn’t look like integration with existing Docker containers will be easy. Flynn apps have to go through the slug builder and runner. Can I push an app with a Dockerfile? Run an existing container image? Conversely, how easy will it be to build a Docker container from a Flynn app, to run it standalone, without the whole platform? From what I could understand, the roadmap of Flynn is driven by the requests made by the organizations sponsoring the development of the project, and those features haven’t been mentioned a lot so far. I hope that it will evolve (or that implementing the missing parts will be easy), since it would mean that in addition of being a PAAS leveraging Docker, Flynn could be the Docker PAAS; i.e. the solution for anyone who is sold on Docker and its concept, and want to take that to the next level.
Also, why the name?
Since Jeff described Flynn as a Grid, I believe that the project is named after this other Flynn ☺
The Grid. A digital frontier. I tried to picture clusters of information as they moved through the computer. What did they look like? Ships? Motorcycles? Were the circuits like freeways? I kept dreaming of a world I thought I’d never see. And then one day… I got in.
Additional reading…
- Flynn dev environment (as a Vagrantfile), including video demo
- Flynn blog post about demo and roadmap, including video of the first meet-up